Gallery Home -> Hadoop_Wikipedia
Hadoop on the Wikipedia
The format of the wikipedia dump is html, with each of the pages having <page> and </page> tags. As my first hadoop project, I set out to look at the lengths of the pages in the Wikipedia. The good folks at Wikipedia have made a dump of the contents of the current versions of all the pages available as a single XML file containing all the text from all the pages. The text in the article is
pages-articles.xml.bz2 – Current revisions only, no talk or user pages. (This is probably the one you want.
The size of the 13 February 2014 dump is approximately 9.85 GB compressed, 44 GB uncompressed).
There is also a much larger version avaiable wich has all the versions of all the pages, but that was beyond the capabilities of the psueudodistributed cluster on the CentOS server in my basement. Wanting to treat this file as a collection of pages presented a bit of a mismatch with the default hadoop inputFormat. This default reads one line as one input to the mapper. In order to have one page be one mapper input, an XmlInputFormat.java extention to the Inputformat was necessary.
This set of programs uses the "new" functions... the ones which had come in by the time I started with hadoop ver 1.2. They use the org.apache.hadoop.mapreduce. bla bla bla imports, not the deprecated .mapred imports. These methods have been tested on both ver 1.2 and ver 2.2.0 The mapper mimics the classic hadoop word count behavior by outputting a the page length as the Key, and the value is 1. I did not implement a combiner. The reducer adds up how many pages have the key's length.
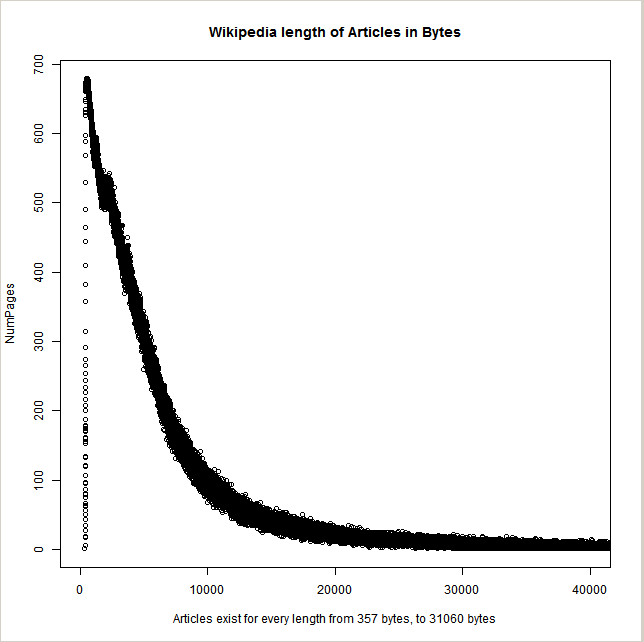
When I got to looking at the output (with R) I observed that the number of pages for a small range of page sizes was quite tight. A correlary
to this is that in the span from page-lengths of 357 to 31060, there is no number of bytes which has no pages. To me
this says that something something about statistical mechanics has crept into the population of wiki page authors and revisers.
There are a few pages which have over 1.7M characters, these are wikipedia log files: things which record who did every update on which page and such like.
I attached the code for the job file, the mapper, the reducer, and the XmlInputFormat below. The I admit that the XmlinputFormat does not give the exact number of bytes in the page... I cleaned up a few multiple spaces at the beginning of each line. I also substitutes spaces for Carridge returns, linefeeds, and tabs.
Copy and use the code freely. Attribution to TPMoyer is appreciated, but not necessary.
package gallery; /* you'll need to change this to match your package name */
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
@SuppressWarnings("unused")
public class WikiLengths {
/* this is intended as a beginners task... read the wikipedia dump file (43GB non zipped) and output the feeder
* a histogram of number of pages vs number of bytes/page (each wikipedia article is one <page> </page>)
*/
private static final transient Logger logger = Logger.getLogger("app");
public static void runJob(String input, String output) throws IOException {
logger.debug("cme@ runJob with input="+input+" output="+output);
Configuration conf = new Configuration();
conf.set("xmlinput.start", "<page>");
conf.set("xmlinput.end", "</page>");
conf.set(
"io.serializations",
"org.apache.hadoop.io.serializer.JavaSerialization,org.apache.hadoop.io.serializer.WritableSerialization"
);
/* these two lines enable bzip output from the reducer */
//conf.setBoolean("mapred.output.compress", true);
//conf.setClass ("mapred.output.compression.codec", BZip2Codec.class,CompressionCodec.class);
SimpleDateFormat ymdhms=new SimpleDateFormat("yyyy-MM-ddTHH:mm:ss"); /* ISO 8601 format */
Job job = new Job(conf, "wikPageLengths "+ymdhms.format(new Date()));
FileInputFormat.setInputPaths(job, input);
job.setJarByClass(WikiLengths.class);
job.setMapperClass (WikiLengthsMapper .class);
/*job.setCombinerClass(WikiLengthsReducer.class); This is how to get a mapper which never completes... specify a reducer with different outputs from it's inputs as a combiner */
job.setReducerClass (WikiLengthsReducer.class);
//job.setNumReduceTasks(0);
job.setInputFormatClass(XmlInputFormat.class);
job.setMapOutputKeyClass(LongWritable.class);
// job.setMapOutputValueClass(LongWritable.class); /* not necessary because reducer outputValueClass matches */
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(LongWritable.class);
Path outPath = new Path(output);
FileOutputFormat.setOutputPath(job, outPath);
FileSystem dfs = FileSystem.get(outPath.toUri(), conf);
if (dfs.exists(outPath)) {
dfs.delete(outPath, true);
}
try {
job.waitForCompletion(true);
} catch (InterruptedException ex) {
//Logger.getLogger(WikiSee2.class.getName()).log(Level.SEVERE, null, ex);
logger.fatal("InterruptedException "+ WikiLengths.class.getName()+" "+ex);
} catch (ClassNotFoundException ex) {
logger.fatal("ClassNotFoundException "+ WikiLengths.class.getName()+" "+ex);
}
}
public static void main(String[] args) {
logger.debug("cme@ main");
try {
runJob(args[0], args[1]);
} catch (IOException ex) {
logger.fatal("IOException "+ WikiLengths.class.getName()+" "+ex);
}
}
}
package gallery; /* you'll need to change this to match your package name */
import java.io.IOException;
import java.util.Iterator;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobID;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.TaskAttemptID;
import org.apache.hadoop.mapreduce.TaskID;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
@SuppressWarnings("unused")
public class WikiLengthsMapper extends Mapper<LongWritable, Text, LongWritable, LongWritable> {
/* output key is InputSplit catenated with _ catenated with the page number
* output value is all the lines between <page> and </page> catenated into one line.
* This value has had all cr's and lf's and leading spaces purged.
*/
private static final transient Logger logger = Logger.getLogger("Map");
public static enum mapCounters{NUMPAGES,MAPID}
@Override
public void map(LongWritable key0, Text value0, Context context) throws IOException, InterruptedException {
/**/logger.setLevel(Level.DEBUG);
if(0==(context.getCounter(mapCounters.NUMPAGES)).getValue()){
/* will use the inputSplit as the high order portion of the output key. */
FileSplit fileSplit = (FileSplit) context.getInputSplit();
Configuration cf = context.getConfiguration();
long blockSize=Integer.parseInt(cf.get("dfs.blocksize"));
context.getCounter(mapCounters.MAPID).increment(fileSplit.getStart()/blockSize);/* the base of this increment is 0 */
logger.debug("MAPID set as "+context.getCounter(mapCounters.MAPID).getValue()+" from FileSplit.start="+fileSplit.getStart()+" and blockSize="+blockSize);
}
//logger.debug("mpm23^K="+key0.get());
//logger.debug("wlm44^K="+key0.get()+" len="+value0.getLength()+" len2="+value0.toString().length()+" V="+value0.toString());
// context.write(
// new LongWritable(value0.getLength())
// ,new LongWritable(1)
// );
context.write(key0,new LongWritable(value0.getLength()));
/* dump the first 3 key value pairs for each inputSplit into the mapper.log file */
if(0==context.getCounter(mapCounters.NUMPAGES).getValue()){
logger.debug(" infile ");
logger.debug(" byte ");
logger.debug(" length offset mapper page");
}
if(3>context.getCounter(mapCounters.NUMPAGES).getValue()){
logger.debug(String.format(
"mpm60^ %5d %12d %4d %10d %s"
,value0.getLength()
,key0.get()
,context.getCounter(mapCounters.MAPID).getValue()+((0<key0.get()?0:1))
,(0<key0.get()?context.getCounter(mapCounters.NUMPAGES).getValue():0)
,value0
)
);
}
context.getCounter(mapCounters.NUMPAGES).increment(1);
}
}
package gallery; /* you'll need to change this to match your package name */
import gallery.WikiLengthsMapper.mapCounters;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.JobID;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.TaskAttemptID;
import org.apache.hadoop.mapreduce.TaskID;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
@SuppressWarnings("unused")
public class WikiLengthsReducer
extends Reducer<LongWritable,LongWritable,NullWritable, LongWritable> {
private static final transient Logger logger = Logger.getLogger("App");
public static enum redCounters{NUMKEYS,REDID}
@Override
public void reduce(LongWritable key1, Iterable<LongWritable> value1s,Context context)
throws IOException, InterruptedException {
/**/logger.setLevel(Level.DEBUG);
//logger.debug("red22^"+key1.get());
if(0==context.getCounter(redCounters.NUMKEYS).getValue()){
String taskId=context.getTaskAttemptID().getTaskID().toString();
logger.debug(String.format("^fr37 setting REDID to %d from %s",Integer.parseInt(taskId.substring(taskId.length()-6)),taskId));
context.getCounter(redCounters.REDID).increment(Integer.parseInt(taskId.substring(taskId.length()-6)));
sayRedContextStuff(context);
}
// int counter=0;
// for(LongWritable v:value1s){
// counter++;
// }
// context.write(key1,new LongWritable(counter));
for(LongWritable v:value1s){
//logger.debug(String.format("29^ %12d %10d", key1.get(),v.get()));
context.write(NullWritable.get(),v);
}
}
public void sayRedContextStuff(Context context) throws IOException, InterruptedException{
logger.debug("cme@ sayRedContextStuff");
/* Used to see what can be seen from here.
* Dumps pretty much everything I could see to the map.log file*/
JobID jid = context.getJobID();
logger.debug("jobName="+context.getJobName()+" jidIdentifier="+jid.getJtIdentifier()+" jid.toString="+jid.toString());
logger.debug("jar="+context.getJar());
Configuration cf = context.getConfiguration();
logger.debug("fs.default.name="+cf.get("fs.default.name"));
Iterator<Entry<String, String>> cfi =cf.iterator();
int counter=0;
while(cfi.hasNext()) {
Entry<String,String> cfItem=cfi.next();
logger.debug(String.format("cfi %4d %-60s %-60s",counter++,cfItem.getKey(),cfItem.getValue()));
}
TaskAttemptID taid=context.getTaskAttemptID();
TaskID tid=taid.getTaskID();
logger.debug("TaskID="+tid.toString());
Path wdir=context.getWorkingDirectory();
logger.debug("workingDirectory path="+wdir);
logger.debug("/*************************************************************************************************************/");
}
}
package gallery; /* you'll need to change this to match your package name */
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DataOutputBuffer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
/**
* Reads records that are delimited by a specifc begin/end tag.
* Correctly handles case where xmlinput.start and xmlinput.end span
* the boundary between inputSplits
*/
public class XmlInputFormat extends TextInputFormat {
private static final transient Logger logger = Logger.getLogger("Map");
public static final String START_TAG_KEY = "xmlinput.start";
public static final String END_TAG_KEY = "xmlinput.end";
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit is,TaskAttemptContext tac) {
/**/logger.setLevel(Level.DEBUG);
return new XmlRecordReader();
}
public static class XmlRecordReader extends RecordReader<LongWritable, Text> {
private byte[] startTag;
private byte[] endTag;
private long start;
private long end;
private FSDataInputStream fsin;
private DataOutputBuffer buffer = new DataOutputBuffer();
private LongWritable key = new LongWritable();
private Text value = new Text();
private boolean denyLeadingSpaces;
private CompressionCodecFactory compressionCodecs = null;
private char space = ' ';
@Override
public void initialize(InputSplit is, TaskAttemptContext tac) throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit) is;
startTag = tac.getConfiguration().get(START_TAG_KEY).getBytes("utf-8");
endTag = tac.getConfiguration().get(END_TAG_KEY ).getBytes("utf-8");
start = fileSplit.getStart();
end = start + fileSplit.getLength();
// this.fileSplit = (FileSplit) split;
// this.conf = context.getConfiguration();
//
// final Path file = fileSplit.getPath();
// compressionCodecs = new CompressionCodecFactory(conf);
//
// final CompressionCodec codec = compressionCodecs.getCodec(file);
// System.out.println(codec);
// FileSystem fs = file.getFileSystem(conf);
Path file = fileSplit.getPath();
Configuration conf=tac.getConfiguration();
compressionCodecs = new CompressionCodecFactory(conf);
final CompressionCodec codec = compressionCodecs.getCodec(file);
logger.debug("codec seen as "+codec);
FileSystem fs = file.getFileSystem(conf);
fsin = fs.open(fileSplit.getPath());
fsin.seek(start);
logger.debug("see first location of the start as "+fsin.getPos());
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
//logger.debug("XRR83^ "+fsin.getPos());
if (fsin.getPos() < end) {
if (readUntilMatch(startTag, false)) {
//logger.debug("XRR86^ "+fsin.getPos());
key.set(fsin.getPos()-startTag.length);
try {
buffer.write(startTag);
denyLeadingSpaces=true;
if (readUntilMatch(endTag, true)) {
value.set(buffer.getData(), 0, buffer.getLength());
//logger.debug("XRR93^key="+key.get()+" value="+value.toString());
return true;
} else if(0!=buffer.getLength()){
logger.debug("false= readUntilMatch but buffer not 0length. This will show only for xmlinput.start with no xmlinput.end tags");
value.set(buffer.getData(), 0, buffer.getLength());
//logger.debug("XRR98^K="+key.get()+" V="+value.toString());
return true;
}
} finally {
buffer.reset();
}
}
} else {
logger.debug("at end position");
}
return false;
}
@Override
public LongWritable getCurrentKey() throws IOException,
InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return (fsin.getPos() - start) / (float) (end - start);
}
@Override
public void close() throws IOException {
fsin.close();
}
private boolean readUntilMatch(byte[] match, boolean withinBlock) throws IOException {
/* this is where the magic of the hadoop FileSystem class comes in... if this does not
* see match within the current inputSplit, it will continue to fsin.read() bytes
* into the next inputsplit.
*/
//logger.debug("cme@ readUntillMatch starting at "+fsin.getPos());
int i = 0;
int lastB=0;
while (true) {
int b = fsin.read();
/* Used to look at a 64MB input slice off the decompressed wikipedia
* dump (latest version of pages only ( the 9GB one)). The logger section below
* shows the two readUntilMatch behaviors. First behavior is seen at the end of
* mapper-the-first. It has been called with match==xmlinput.end It continues
* reading past the file-split in log file !!! yourjobIdBelowHere !!!
* http://localhost.localdomain:50060/tasklog?attemptid=attempt_201310220813_0030_m_000000_0&all=true
* The second behavior is when readUntilMatch is called with match==the xmlinput.start
* at the beginning of the map-00001 (second input split).
* http://localhost.localdomain:50060/tasklog?attemptid=attempt_201310220813_0030_m_000001_0&all=true
* By reading up to the xmlinput.start it ignores the partial page "overRead" by mapper-just-prior
*/
// if( (fsin.getPos()>=67108864) /* the beginning of split the second */
// &&(fsin.getPos()<=67158079) /* for the version of wikipedia I grabbed, bendodiazapine started at byte 67042129 and ended at 67157331 (spanning the 0th and 1st input splits)*/
// ){
// /**/logger.debug(String.format("%10d byte=%3d %c",fsin.getPos(),b,(char)b)); /* mapper log gets 1 line per inputfile byte */
// }
if (b == -1)return false; /* end of file */
denyLeadingSpaces=((denyLeadingSpaces&&(32==b))||(10==b)||(13==b))?true:false;
// save to buffer:
if (withinBlock){
if( (b!=10)
&&(b!=13)
&&(b!= 9)
&&((b!=32)||(false==denyLeadingSpaces)||(lastB!=32))
){
buffer.write(b);
lastB=b;
}
else
if( (b==10)
||(b==13)
||(b== 9)
){
buffer.write(space);
lastB=32;
}
}
// check if we're matching:
if (b == match[i]) {
i++;
if (i >= match.length)return true;
} else
i = 0;
// see if we've passed the stop point:
if (!withinBlock && i == 0 && fsin.getPos() >= end)return false;
}
}
}
}
package gallery; /* you'll need to change this to match your package name */
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DataOutputBuffer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
/**
* Reads records that are delimited by a specifc begin/end tag.
* Correctly handles case where xmlinput.start and xmlinput.end span
* the boundary between inputSplits
*/
public class XmlInputFormatNoSpaces extends TextInputFormat {
private static final transient Logger logger = Logger.getLogger("Map");
public static final String START_TAG_KEY = "xmlinput.start";
public static final String END_TAG_KEY = "xmlinput.end";
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit is,TaskAttemptContext tac) {
/**/logger.setLevel(Level.DEBUG);
return new XmlRecordReader();
}
public static class XmlRecordReader extends RecordReader<LongWritable, Text> {
private byte[] startTag;
private byte[] endTag;
private long start;
private long end;
private FSDataInputStream fsin;
private DataOutputBuffer buffer = new DataOutputBuffer();
private LongWritable key = new LongWritable();
private Text value = new Text();
private boolean denyLeadingSpaces;
private CompressionCodecFactory compressionCodecs = null;
@Override
public void initialize(InputSplit is, TaskAttemptContext tac) throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit) is;
startTag = tac.getConfiguration().get(START_TAG_KEY).getBytes("utf-8");
endTag = tac.getConfiguration().get(END_TAG_KEY ).getBytes("utf-8");
start = fileSplit.getStart();
end = start + fileSplit.getLength();
// this.fileSplit = (FileSplit) split;
// this.conf = context.getConfiguration();
//
// final Path file = fileSplit.getPath();
// compressionCodecs = new CompressionCodecFactory(conf);
//
// final CompressionCodec codec = compressionCodecs.getCodec(file);
// System.out.println(codec);
// FileSystem fs = file.getFileSystem(conf);
Path file = fileSplit.getPath();
Configuration conf=tac.getConfiguration();
compressionCodecs = new CompressionCodecFactory(conf);
final CompressionCodec codec = compressionCodecs.getCodec(file);
logger.debug("codec seen as "+codec);
FileSystem fs = file.getFileSystem(conf);
fsin = fs.open(fileSplit.getPath());
fsin.seek(start);
logger.debug("see first location of the start as "+fsin.getPos());
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
//logger.debug("XRR83^ "+fsin.getPos());
if (fsin.getPos() < end) {
if (readUntilMatch(startTag, false)) {
//logger.debug("XRR86^ "+fsin.getPos());
key.set(fsin.getPos()-startTag.length);
try {
buffer.write(startTag);
denyLeadingSpaces=true;
if (readUntilMatch(endTag, true)) {
value.set(buffer.getData(), 0, buffer.getLength());
//logger.debug("XRR93^key="+key.get()+" value="+value.toString());
return true;
} else if(0!=buffer.getLength()){
logger.error("false= readUntilMatch but buffer not 0length. This will show only for xmlinput.start with no xmlinput.end tags");
value.set(buffer.getData(), 0, buffer.getLength());
//logger.debug("XRR98^K="+key.get()+" V="+value.toString());
return true;
}
} finally {
buffer.reset();
}
}
} else {
logger.debug("at end position");
}
return false;
}
@Override
public LongWritable getCurrentKey() throws IOException,
InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return (fsin.getPos() - start) / (float) (end - start);
}
@Override
public void close() throws IOException {
fsin.close();
}
private boolean readUntilMatch(byte[] match, boolean withinBlock) throws IOException {
/* this is where the magic of the hadoop FileSystem class comes in... if this does not
* see match within the current inputSplit, it will continue to fsin.read() bytes
* into the next inputsplit.
*/
//logger.debug("cme@ readUntillMatch starting at "+fsin.getPos());
int i = 0;
while (true) {
int b = fsin.read();
/* Used to look at a 64MB input slice off the decompressed wikipedia
* dump (latest version of pages only ( the 9GB one)). The logger section below
* shows the two readUntilMatch behaviors. First behavior is seen at the end of
* mapper-the-first. It has been called with match==xmlinput.end It continues
* reading past the file-split in log file !!! yourjobIdBelowHere !!!
* http://localhost.localdomain:50060/tasklog?attemptid=attempt_201310220813_0030_m_000000_0&all=true
* The second behavior is when readUntilMatch is called with match==the xmlinput.start
* at the beginning of the map-00001 (second input split).
* http://localhost.localdomain:50060/tasklog?attemptid=attempt_201310220813_0030_m_000001_0&all=true
* By reading up to the xmlinput.start it ignores the partial page "overRead" by mapper-just-prior
*/
// if( (fsin.getPos()>=67108864) /* the beginning of split the second */
// &&(fsin.getPos()<=67158079) /* for the version of wikipedia I grabbed, bendodiazapine started at byte 67042129 and ended at 67157331 (spanning the 0th and 1st input splits)*/
// ){
// /**/logger.debug(String.format("%10d byte=%3d %c",fsin.getPos(),b,(char)b)); /* mapper log gets 1 line per inputfile byte */
// }
if (b == -1)return false; /* end of file */
denyLeadingSpaces=((denyLeadingSpaces&&(32==b))||(10==b)||(13==b))?true:false;
// save to buffer:
if (withinBlock){
if( (b!=10)
&&(b!=13)
&&(b!=32)
&&(b!= 9)
){
buffer.write(b);
}
}
// check if we're matching:
if (b == match[i]) {
i++;
if (i >= match.length)return true;
} else
i = 0;
// see if we've passed the stop point:
if (!withinBlock && i == 0 && fsin.getPos() >= end)return false;
}
}
}
}